
Building Evals that Work
How do you encode human judgment into a machine, and how do you know when it’s working?

Over the past few months, I’ve heard the same complaint from half a dozen AI founders across different sectors: their eval infrastructure doesn’t tell them why a customer interaction failed. The dashboards they wired up catch regressions but can’t explain them. When something goes wrong, the team ends up digging through raw traces by hand, trying to work out what went wrong.
I’ve been trying to understand why, and what the teams who’ve solved it are doing differently. Building reliable evals is a stress test for the deeper problem every AI team faces: how do you encode human judgment into a machine, and how do you know when it’s working?
If you’ve built evals that hold up in production, I’d love to hear from you. I’ll publish a longer piece on this in the coming weeks.
Links
I like this idea of teams learning from each other by prompting in public. Will figure out how to implement it at Airtree and report back:

The future of onboarding:






Insights from China’s AI labs:

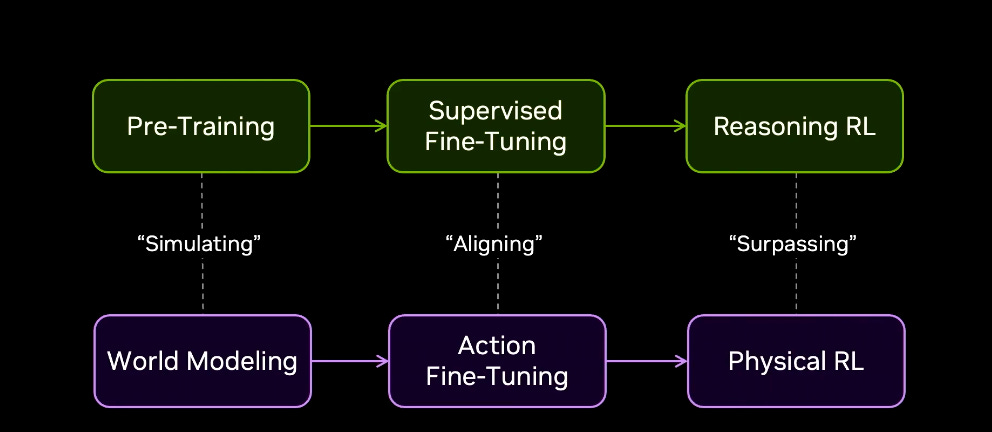
Jim Fan on the path for Physical AI, I liked the chart (pasted below) where he builds the parallel with LLM evolution:



This is how I built my Personal CRM:


The L1-L5 scale for embodied robotics (analogous to the AV scale):

Tracks
I can’t believe Spotify was already 3 years old when I joined, it had about 100 (terrible) songs when I signed up. My all time tracks here - probably weighted towards 2016 listening:

Love Thylacine (h/t Nick Crocker who introduced me to him)